The Data Quality Landscape Analysis
Data quality has been an issue since the dawn of computing. As soon as human beings are involved with entering data into a computer system, there is the possibility of that data being incomplete, out of date, mistyped, or just plain wrong. This creates issues for companies that monitor their business performance, for example, wanting to understand their customers or the performance of their products. Despite data quality software solutions having existed for many decades, maintaining high data quality has long been an intractable problem. In survey after survey in recent years, only around a third of executives completely trust their corporate data. This is partly due to data entry problems and human nature, but also due to data being duplicated in different systems across an enterprise. Poor data quality has substantial costs. The US Network for Excellence in Health Innovation estimates that errors in prescriptions alone cost $21 billion and cause 7,000 deaths annually. Data quality issues apply to all industries, with costs associated with higher than necessary operational costs, wasted resources, compliance issues and fines, reputational damage and poor business decisions based on incorrect or incomplete data.
Data quality solutions offer a range of functionality to improve this state of affairs. Software can profile data to reveal statistical anomalies, can detect likely duplicate records, find incomplete data records and suggest ways to merge possible duplicates. Data can be enriched, for example by automatically adding a postal code to a customer record, but also in more elaborate ways by use of 3rd party datasets. Examples of this include adding the voting district of an address, some demographic data for that area or more esoteric information such as whether an address is based in a flood plain, which is useful for an insurance company. Data quality software has traditionally used rules to determine and improve data quality, and to speed things up it has for many years employed machine learning to partially automate data quality processes. Recently we have seen greater use of generative AI in some contexts, and the use of various flavours of AI to automate the detection of anomalies and issues in data records, in some cases fixing the data problems automatically and in other cases flagging suspect records for human intervention. While the industry has traditionally focused on structured data, there is greater emphasis now on considering the data quality in unstructured forms such as documents, emails, spreadsheets etc. Modern tools frequently use AI to automatically read and classify data from documents and help with monitoring its quality,
The data quality used to be quite fragmented, with different software products for data profiling, for merge matching, data cleansing and data enrichment. Over time these merged into broader data quality suites that could carry out pretty much all necessary data quality functionality. In turn, these features have become embedded in broader data management solutions, such as within master data management tools or wider platforms that include data integration and data governance capabilities. This consolidation has seen many vendors acquired and their software embedded into broader suites. Nonetheless, there have also been new market entrants appearing, often touting extensive use of AI. A data observability market has started to emerge alongside the traditional data quality market, with an emphasis on monitoring the health, lineage and performance of data pipelines in an enterprise, including anomaly detection and resolution. This market overlaps significantly with the general data quality market, and it is likely that its vendors will expand their functionality into other data quality aspects, while traditional data quality vendors will add more data observability features. This follows the historical parallel of data quality initially being subdivided into separate markets like profiling and merge/matching before consolidating into broader offerings.
Both data quality and data observability are multi-billion-dollar markets, with the latter showing more rapid growth recently, while data quality is a more mature market. Estimates vary by analyst and what exactly is included, but the data quality market is roughly a $4 billion market with growth of around 9%, compared to around 12% for the general enterprise software market.
The data quality market has had an injection of emphasis by the widespread interest in generative AI. For most enterprise applications of generative AI, it is necessary to supplement the raw large language models (LLMs) used with company-specific data, such as customer history data, product manuals or specifications, or contract information. LLMs are highly dependent on their training data and the data that they have access to, so if an enterprise supplements an LLM with additional datasets then it is crucial that those datasets have good quality data in them. In a sense, the success of most generative AI implementations is heavily dependent on the data that they are basing their answers on.
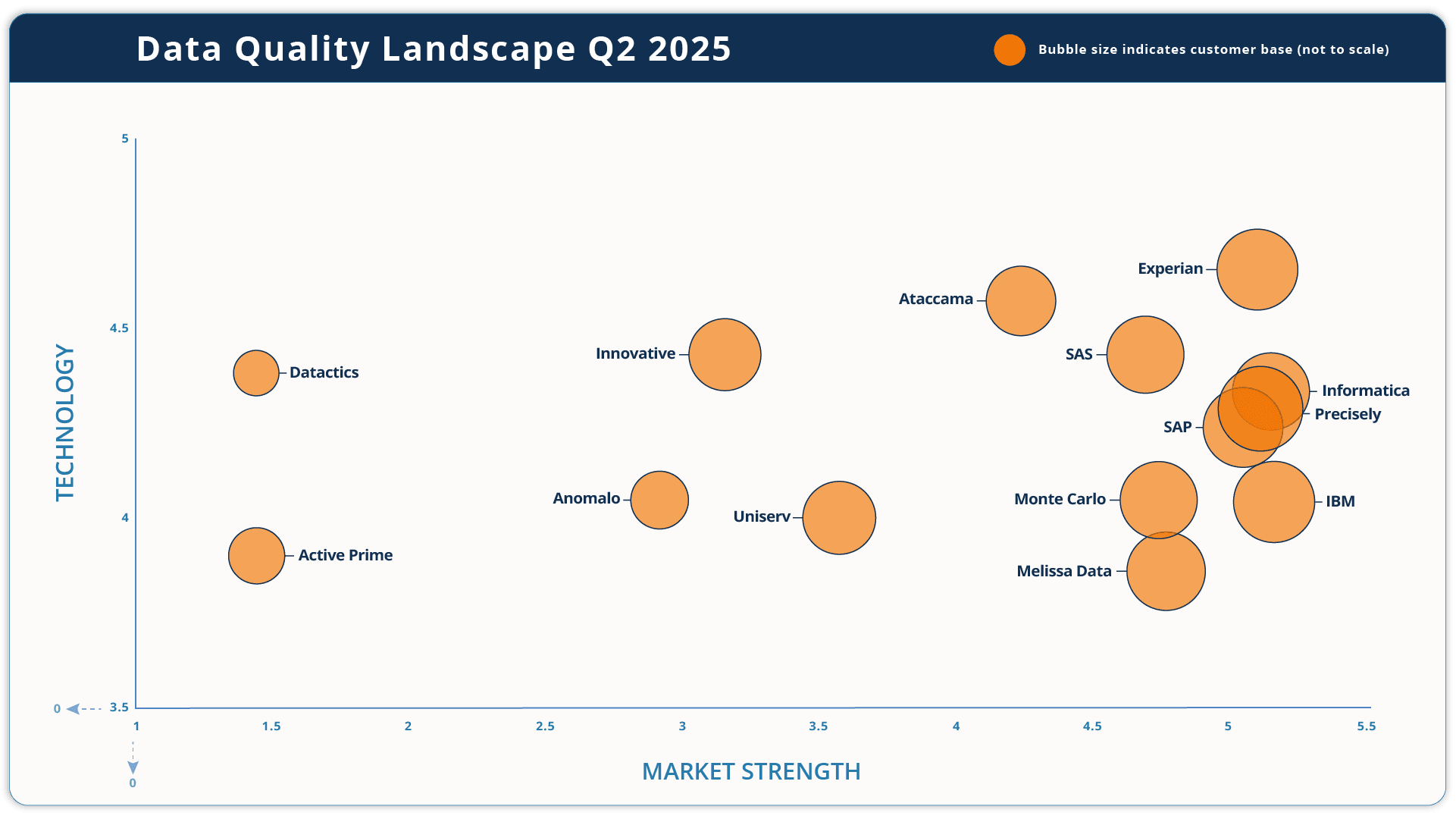
The diagram that follows shows the major data quality vendors, displayed in three dimensions. See later for definitions of these.