
The Big Data Warehouse Landscape Analysis
The data warehouse had its origins in the 1980s, a dedicated database aimed at supporting management decisions, gathering data from disparate operational systems into a single, trusted source of data. The need arose because in any large organization there are typically many (possibly hundreds) of operational systems that capture and process the basic transactions of a business. Such transactions might be, for example, a purchase at a shop, a new contract with a business or a new patient at a hospital. There have been many attempts to rationalise and standardise these core transaction systems over the years, but such efforts have only succeeded partially. Today a large enterprise has, on average, over a hundred significant applications (according to multiple surveys), only one of which may be their core ERP system, which itself may have multiple separate instances. To track the progress of a patient through a hospital, or assess the profitability of a customer or product, it is necessary to have a consistent set of data about core transactions and the context of those transactions. For example, a purchase of a can of soup at a store involves a product, a customer, a price, a payment etc. A data warehouse aims to provide a single, authoritative database that combines a record of all business transactions with the necessary contextual data to make sense of that transaction. Subsets of the data may be generated from the warehouse for particular departments or specific business analytic uses (“data marts”). A whole industry of data integration and data quality technologies evolved alongside in order to merge the many, often inconsistent and incomplete, data sources into a trusted corporate resource. A further industry of reporting and analytic tools was developed in order to make sense of the data held within the data warehouse.
The software industry has provided a range of database products that are suitable for data warehouses, from general purpose relational databases to specialist databases aimed specifically for analytic workloads. As data warehouses increased in size, there were more demands for near real-time access to analytics. While ever-growing data warehouses presented performance and scalability challenges to traditional relational databases. We saw the advent of columnar databases, which are more generally efficient for analytic workloads at the expense of limitations elsewhere. Multi parallel processing (MPP) databases allowed heavy query workloads to be split amongst many processors rather than a single processor (SMP). The advent of cloud computing further commoditised processing capacity, memory and storage. These developments allowed data warehouses to grow hugely in scale, from a few terabytes (the largest data warehouse in 2003 was 30 TB) into the 100+ petabytes range that we see in the largest data warehouses today, more than a thousandfold increase in two decades. “Data lakes” utilising cheap file systems for storage on a huge scale have allowed vast amounts of raw data to be stored using technologies such as Apache Spark. However, a data lake is mostly the preserve of data scientists and are generally regarded as complementary to a data warehouse rather than a competitor to it.
In recent years there has been a broad, if gradual, movement of applications from on-premise data centres to cloud technologies, whether private cloud, public cloud, or a hybrid of these. Data warehouses have naturally followed suit, and the traditional database vendors Oracle, IBM and Microsoft have seen major new cloud data warehouse challengers in the form of Snowflake, Amazon Redshift and Google BigQuery, amongst others. Only about a fifth of companies now have data warehouses exclusively on premise.
The major vendors in the market are summarised in the diagram below.
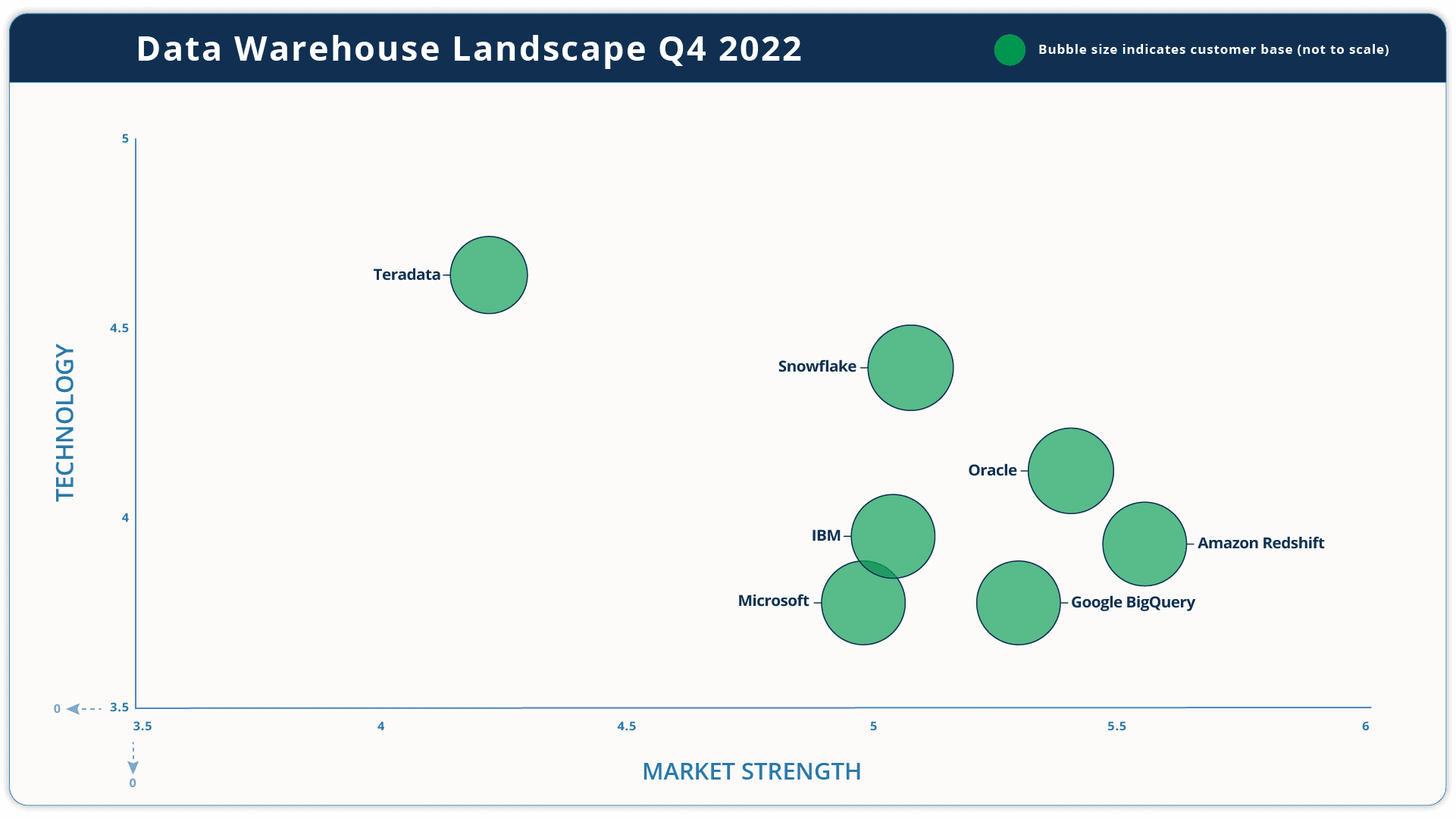
The landscape diagram represents the market in three dimensions. The size of the bubble represents the customer base of the vendor, i.e. the number of corporations it has sold data warehouse software to, adjusted for deal size. The larger the bubble, the broader the customer base, though this is not to scale. The technology score is made up of a weighted set of scores derived from: customer satisfaction as measured by a survey of reference customers1, analyst impression of the technology, maturity of the technology in terms of its time in the market and the breadth of the technology in terms of its coverage against our functionality model. Market strength is made up of a weighted set of scores derived from: data warehouse revenue, growth, financial strength, size of partner ecosystem, customer base (revenue adjusted) and geographic coverage. The Information Difference maintains vendor profiles that go into more detail. Customers are encouraged to carefully look at their own specific requirements rather than high-level assessments such as the Landscape diagram when assessing their needs.
A significant part of the “technology” dimension scoring is assigned to customer satisfaction, as determined by a survey of vendor customers. In this annual research cycle the vendors with the happiest customers was Teradata. Our congratulations to them.
__________
[1] In the absence of sufficient completed references, a neutral score was assigned to this factor
Below is a list of the significant data warehouse vendors.
| Vendor | Brief Description | Website |
|---|---|---|
| 1010 Data | Provides column-oriented database and web-based data analysis platform. | www.1010data.com |
| Actian | Actian's product is an analytic database on commodity hardware. | www.actian.com |
| Alibaba | The Oceanbase distributed cloud-based data warehouse is Alibaba’s data warehouse offering. | www.alibabacloud.com/product/oceanbase |
| Amazon Redshift | Cloud-based data warehouse solution. | www.aws.amazon.com/redshift/ |
| Cloudera | Enterprise cloud vendor incorporating Hortonworks, with a data warehouse offering. | www.cloudera.com |
| Databricks | Data “lakehouse” vendor. | www.databricks.com |
| Exasol | German data warehouse appliance vendor. | www.exasol.com |
| Greenplum | Vendor aiming at high-end warehouses, now part of Pivotal, a subsidiary of EMC, itself acquired by Dell in 2015. | pivotal.io/big-data/pivotal-greenplum |
| HPCC | An open-source, massively parallel platform for big data processing, developed by LexisNexis Risk Solutions. | www.hpccsystems.com |
| IBM | DB2 is the data warehouse software offering from the industry giant, now available on cloud as well as on-premise. | www.ibm.com |
| InfoBright | Provides a columnar-database analytics platform. | www.infobright.com |
| jSonar | Boston-based NoSQL data warehouse vendor. | www.jsonar.com |
| Magnitude | Part of Magnitude Software, Kalido is an application to automate building and maintaining data warehouses. | www.magnitude.com |
| MarkLogic | Enterprise NoSQL database vendor. | www.marklogic.com |
| Microsoft | As well as its SQL Server relational database, Microsoft acquired Data Allegro and at the end of 2010 launched its Parallel Warehouse based on this technology. | www.microsoft.com |
| MonetDB | MonetDB is an open-source columnar database system for high-performance applications. | www.monetdb.cwi.nl |
| Neo4j | Open source graph database. | www.neo4j.org |
| Oracle | Database and applications giant with its own data warehouse appliance. | www.oracle.com |
| ParStream | Columnar, in-memory, MPP database vendor aimed at analytic processing. | www.parstream.com |
| Pivotal | Owners of the Greenplum massively parallel data warehouse solution, now an open-source solution. | pivotal.io/big-data/pivotal-greenplum |
| Qubole | Markets the Qubole Data Service, which accelerates analytics workloads working on data stored in cloud databases. | www.qubole.com |
| Sand | Focuses on allowing customers to effectively retain massive amounts of compressed data in a near-line repository for extended periods. | www.sand.com |
| SAP/Sybase | Sybase was a pioneer in column-oriented analytic database technology, acquired in mid-2010 by giant SAP. SAP also offers the in-memory database technology HANA. | www.sap.com |
| SAS Institute | Comprehensive data warehouse technology from the largest privately owned software company in the world. | www.sas.com |
| Snowflake | Cloud-only data warehouse vendor. | www.snowflake.com |
| Teradata | Database giant with its own data warehouse solutions. | www.teradata.com |
| Vertica | Data warehouse appliance vendor Vertica was purchased by HP in 2011. | www.vertica.com |
| WhereScape | Not an appliance, but a framework for the development and support of data warehouses. | www.wherescape.com |
| XtremeData | US vendor that provides highly scalable cloud database platform. | www.xtremedata.com |
| Yellowbrick | Cloud data warehouse vendor. | www.yellowbrick.com |