

What is best practice for organisations deploying AI in the enterprise? In this blog we examine the organisation, governance, architecture, processes, culture and technology needed for effective AI deployment.
To begin with, an organisation needs to consider why it is considering deploying AI in the first place, just as it would with any new technology. What is the business case? It may be a strategic infrastructure decision, but it should not be just based on “fear of missing out”. It should be possible to identify either potential cost savings through greater automation or new opportunities, such as more tailored marketing or enhanced customer experiences. The exact nature of the savings or potential new revenue will vary from industry to industry and company to company, but this exercise should always be undertaken. The costs of implementing an AI infrastructure are not trivial, and these very real costs should be balanced against realistic, plausible benefits.
To give an example, “Deploying AI to automate claims processing aligns with a goal of reducing claims cycle time by 50%” might be an example project in an insurance company, and it should be possible to estimate what financial impact a 50% improvement in claims cycle time would bring. That would be a potential benefit to offset against the cost of AI investment.
Once costs and benefits have both been estimated, then it will be possible to draw up a multi-year business case, including calculating the payback period, net present value (NPV) and internal rate of return (IRR) of the AI investment, just like any major new investment. Bear in mind that the current success rate of AI projects is low. A large MIT study in 2025 found that 95% of AI projects fail to deliver any return on investment whatsoever, and other similar studies have estimated success rates only marginally better. Given this, it makes sense to apply a high discount rate to the business case, since the level of uncertainty is clearly high. A company typically uses a discount rate based on its weighted average cost of capital. In practice, this means that most companies use a discount rate between 8% and 15%. For low-risk projects, it may be reasonable to use a figure at the low end of the range, but for high-risk projects, such as venture capital investments, the discount rate should be higher, say 15-20% or even more. Given the current failure rates of AI projects, a high discount rate would be prudent.
Let’s assume that this has been done and the AI investment project is approved. What organisational structures makes sense? This will vary from company to company depending on culture and what is in place, but you should consider setting up an AI centre of excellence that can set standards, select technology for the enterprise and guide deployments. This should be responsible for knowledge sharing, governance, and reuse of AI models. You will want executive sponsorship of this, and an ethics and governance person or team to monitor privacy, model bias and regulatory compliance (there are various pieces of AI-related legislation appearing, such as the EU AI Act, which came into force in August 2024). This group needs to consider operational, reputational, regulatory, and ethical risks before deployment, and implement bias detection tools and review mechanisms.
A broader consideration is company culture. Employees need to be educated on AI capabilities and limitations. Ideally, a culture should be encouraged that promotes collaboration between technical teams and business units, and encourages experimentation and learning from failures.
With regards to architecture, you should consider several layers:
- Data
- Model
- Integration
- Monitoring
- Security.
Generative AI in particular is heavily dependent on data, whether that is the data it was initially trained on or supplementary data that it is exposed to. The latter may be by using a retrieval augmented generation (RAG) approach to extend an LLM’s knowledge to company-specific datasets like product manuals, policy manuals or corporate databases. Ideally, you want a data layer that is robust, scalable, and flexible. Key components include centralised, managed, and governed data lakes or data warehouses. These should be the basis for high-quality data, both structured and unstructured, with consistent metadata. The architecture should include data versioning and lineage for reproducibility and auditability. It should also include a data quality component, including ongoing monitoring.
Separate from the data model should be a model layer. This should separate data pre-processing, model training, and serving. It may employ microservices or containerised deployment, such as using Docker or Kubernetes for scalability. A model registry and model cards should keep track of model versions, metadata, and lineage.
A separate integration layer should ensure that AI outputs integrate seamlessly with enterprise applications (CRM, ERP, supply chain systems etc.). This may be using APIs or an event-driven architecture for real-time data.
A separate monitoring and observability layer should be established to monitor model performance, model drift, bias, latency and data anomalies, including alerts for errors found in production.
Underlying all this should be a security and compliance layer. This layer should include access controls, privilege principles for models and data, and encryption of sensitive data, both at rest and in transit. LLMs have a series of specific security weaknesses such as prompt injection and data poisoning, and these risks need to be mitigated. This is especially the case if AI agents are being considered. These have access to data and resources and so are a particularly juicy target for attackers.
Now consider the processes that we need for AI deployment. Start with problem definition and use case selection. It seems obvious, but it makes sense to prioritise high-value problems that have a strong business case. To make assessments, you will need to assess the feasibility of each potential project, looking at complexity, data availability, business urgency and commitment, and return on investment measure as we discussed earlier. There is then a stage of data preparation, which involves setting up data pipelines, data labelling and reproducible workflows. Next, we need to consider model development and validation. Here we need to stress test models for bias and fairness, document assumptions and limitations, and test models for unusual edge cases. Next is deployment and integration. Here we set up data and application integration, including careful testing to validate the performance of the models under production conditions. Once the model is deployed then we move to monitoring and maintenance, where we track model drift accuracy, and performance and ensure that compliance monitoring is being carried out. If necessary, new data feeds may need to set up or existing ones modified, and it is possible that models (such as machine learning models) may need to be retrained on new data periodically. Finally, there is a governance and auditing process, including the documentation of ownership, decisions, model changes and approvals, and an ongoing regular audit of models for bias and regulatory compliance.
Finally, we need to consider the technology to be deployed. An AI technology architecture is the structured framework that defines how data, models, infrastructure, and applications interact to deliver AI capabilities effectively at scale. It typically combines elements of data engineering, machine learning, operations, software systems, and governance. The main elements of a modern AI technology architecture are as follows.
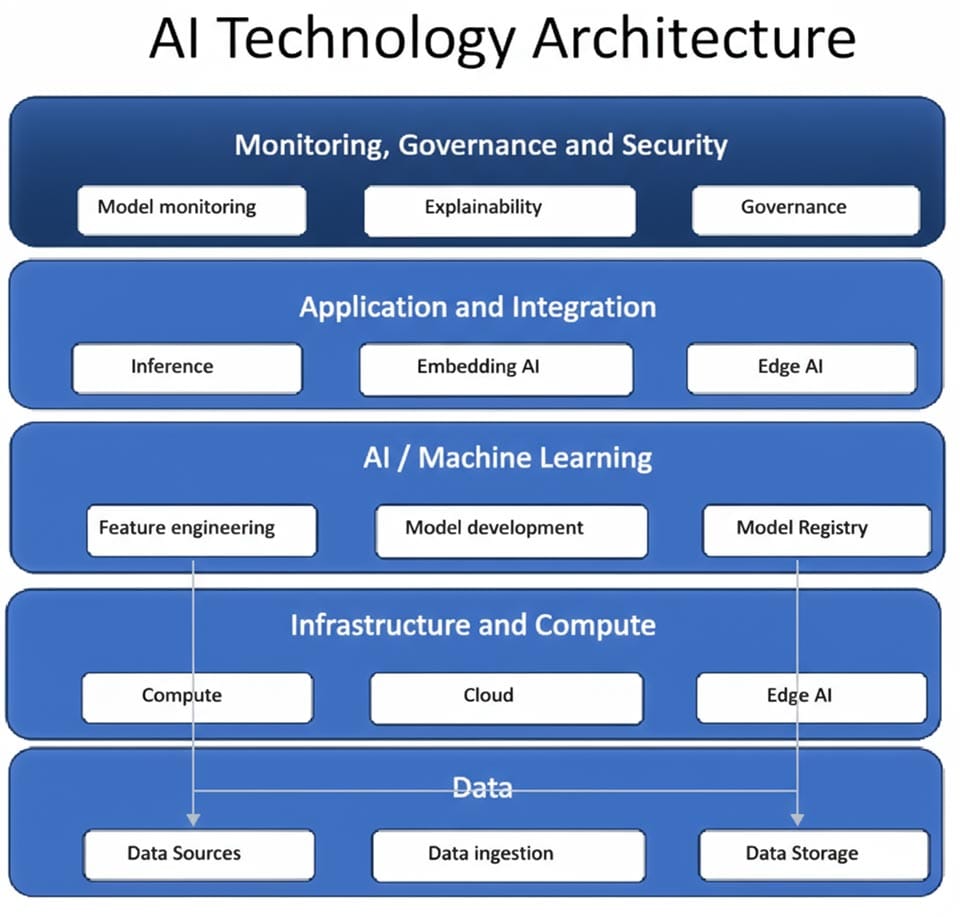
The data layer is the foundation of the AI technology architecture, since a lot depends on data quality and accessibility. As mentioned earlier, this includes data sources, both internal systems (ERP, CRM, supply chain etc) and external sources (APIs, web data, partner systems, public datasets). Then we have data ingestion i.e. data pipelines that collect and move data (either batch or streaming). Data Storage may be data lakes (based on say, Databricks or S3 or Azure Data Lake), and/or data warehouses (based on Snowflake or traditional relational databases). Next is data processing & transformation, with either extract transform and load (ETL) or extract, load and transform (ELT) processes for cleaning, transforming, normalizing, and enriching data. Finally, there is a layer for metadata & cataloguing, with tools for data discovery lineage tracking (e.g., Collibra, Alation etc).
Next there is an AI/machine learning layer, the core of the architecture. Key components include “feature engineering”, with extraction, transformation, and storage of reusable features (a feature store). There is model development for model training and experimentation (using frameworks like TensorFlow or PyTorch), and model evaluation and validation for testing of accuracy, bias, robustness, and generalisation. Then we have a model registry: a central repository for storing and versioning trained models, and machine learning operations (MLOps) pipelines: continuous integration/continuous delivery (CI/CD) for machine learning, covering automating training, testing, deployment, and monitoring.
The infrastructure and compute layer provides the computational backbone to run data and model workloads. The main components are compute resources i.e. CPUs, GPUs, TPUs, or cloud-based AI accelerators. There will be containerization and orchestration using tools like Docker and Kubernetes to manage scalable AI workloads. A cloud or hybrid Infrastructure contains cloud-native services (like AWS SageMaker, Azure ML, GCP Vertex AI) or hybrid setups. Then there is storage and networking, containing high-throughput, low-latency systems for data and model access.
The application and integration layer is where AI models interact with business applications or users. Key components of this are inference and serving, application integration, which is embedding AI into applications, dashboards, chatbots, or automation systems, as well as edge or on-device AI, where lightweight models run on mobile devices. Finally, there is a feedback loop to capturing predictions, outcomes, and user interactions for continuous learning.
The monitoring, governance and security layer ensures reliability, ethics, and compliance in AI systems. Key components of this are model monitoring to detect performance drift, data drift, and anomalies, as well as explainability and transparency. This may have tools to interpret machine learning model decisions (such as SHAP or LIME). There is also data and model governance, which contains policies for access, versioning, and compliance (such as GDPR or ISO 42001). Finally, we have security to protect data, models, and APIs from attacks and audit and logging for end-to-end traceability of data and model decisions.
The orchestration and workflow management layer coordinates complex processes across all layers. Key elements of this are workflow orchestration (perhaps using tools like Airflow, Kubeflow, Prefect, or Dagster for pipeline management), automation and scheduling for retraining, data refresh, and deployment, and experiment tracking: This may use tools like the open source MLflow for reproducibility.
Additionally, for a modern architecture, there may also be a knowledge & semantic layer. One component of this is vector databases and embeddings for semantic search and retrieval (either through specialist databases like Pinecone or FAISS, or through vector search capabilities of existing databases). Another is knowledge graphs, representing entities and relationships, in order to enhance analytics. There may also be RAG (Retrieval-Augmented Generation), used for integrating LLMs with contextual data such as company-specific documents, like policies or technical manuals.
By putting this kind of structure in place, you reduce the chance of falling into common AI pitfalls. These include overestimating return on investment, issues of poor data quality, overlooking data drift and ignoring privacy issues on sensitive data. It is common to simply select the wrong kind of model for the task in hand, fudging testing or leaving open security loopholes. A lack of ethics and bias oversight can lead to embarrassing failures like the Amazon recruitment system fiasco. A lack of cultural engagement and training in a business can cause resistance from employees or a disconnect between business and technical staff. A lack of robust operational processes can lead to projects deteriorating in performance or be unreliable, causing distrust among staff.
In summary, there are a range of things to be considered when deploying AI in the enterprise, from initial business case to the various elements of organisation, governance, architecture, processes, culture and technology. The key to remember is that AI is not a silver bullet, but a technology that has to be managed across a lifecycle like any other new technology. If you are to succeed with it, then the organisational structure and processes that you put in place are just as important as the technology itself.





