The Data Quality Landscape Analysis
Data is the new oil
“Data is the new oil” was a phrase coined in 2006 by entrepreneur Clive Humby, and it is even more true now than it was at that time. We are all increasingly dependent on data, from structured data such as that held within the databases of banks and governments, to the unstructured data of documents, emails, social media posts, audio, images and video files. Since much of that data is entered by humans, there has always been concern about its quality. Indeed, the first data quality tools emerged as far back as the late 1960s. We are all familiar with minor data quality issues, such as, for example, receiving duplicate marketing materials in the post. But for corporations and governments, data quality is a much more serious affair. Various studies have estimated the cost of poor data quality to be as much as $3.1 trillion, according to Harvard Business Review and IBM. The MIT Sloan Management Review reckoned that poor data quality could cost as much as 15% or more of revenue for a company. The US Network for Excellence in Health Innovation estimates that errors in prescriptions alone cost $21 billion and cause 7,000 deaths annually.
Functionality
The data quality industry has grown to help address these issues. Software suites have been developed with extensive data quality capability, from data profiling through to record matching, data de-duplication, data cleansing and data enrichment. Data quality rules have traditionally been entered manually by business users, but in recent years, more and more emphasis has been placed on artificial intelligence, such as machine learning, to generate such rules automatically.
Modern data quality tools
Modern data quality and observability tools can suggest data quality rules based on patterns in the data, can detect anomalies in the data that emerge over time, and suggest or even automate corrective actions when errors are detected. This newer market of data observability has grown alongside the traditional data quality market, and these segments are starting to overlap. Traditional data quality tools have been adding data observability functionality such as anomaly detection and real-time monitoring. Similarly, some data observability vendors have been adding traditional data quality capability such as validity checks. At present, observability vendors focus mostly on detecting issues rather than fixing them, but it seems likely that the two strands of the industry will continue to overlap and gradually merge. For the purposes of this report, we treat data quality and data observability as a single overall market, while acknowledging the distinctions between the market focus of the vendors. These two market subsets are broadly of a similar size in 2026, with data quality around $3 billion in size and data observability around $2-3 billion in size, depending on exactly what is included and excluded. Both are growing at a compound annual growth rate of 11% or more, depending on which sources you believe.
The rise of AI
The rapid rise of AI has created new issues and opportunities for data quality. Large language models (LLMs), the technology underlying generative AI, are heavily dependent on their training data and the other data that they may be exposed to. Companies may use retrieval augmented generation (RAG) to open up corporate documents like policy manuals, technical specifications and product documentation to LLMs. The quality of corporate data, often in an unstructured form, is now under scrutiny. Traditional data quality vendors have focused on the quality of data within structured databases, but are now starting to address unstructured data. At this stage, much of this effort is on structured outputs derived from unstructured sources, rather than the raw unstructured data itself. In future, we may see these tools addressing semantic quality scoring, as more emphasis is placed on the quality of data in unstructured files such as text and images.
Use of AI in data quality
Just as the rise of widespread corporate AI projects has given data quality greater visibility and urgency, data quality tools have themselves started to use more AI internally. Machine learning is used for anomaly and outlier detection and data pipeline drift, while natural language processing is used for interpreting metadata descriptions, document content and name matching. Some tools now use AI to suggest data quality rules automatically and classify datasets without manual intervention. Such tools can give greater context awareness. For example, a city name might be correct in itself but be wrong in the context of which state it is in. Similarly, a product price of zero might be flagged as an error, but may not actually be if it is part of a promotion or sample. Overall, the rise of AI has given the formerly rather staid data quality industry a new lease of life.
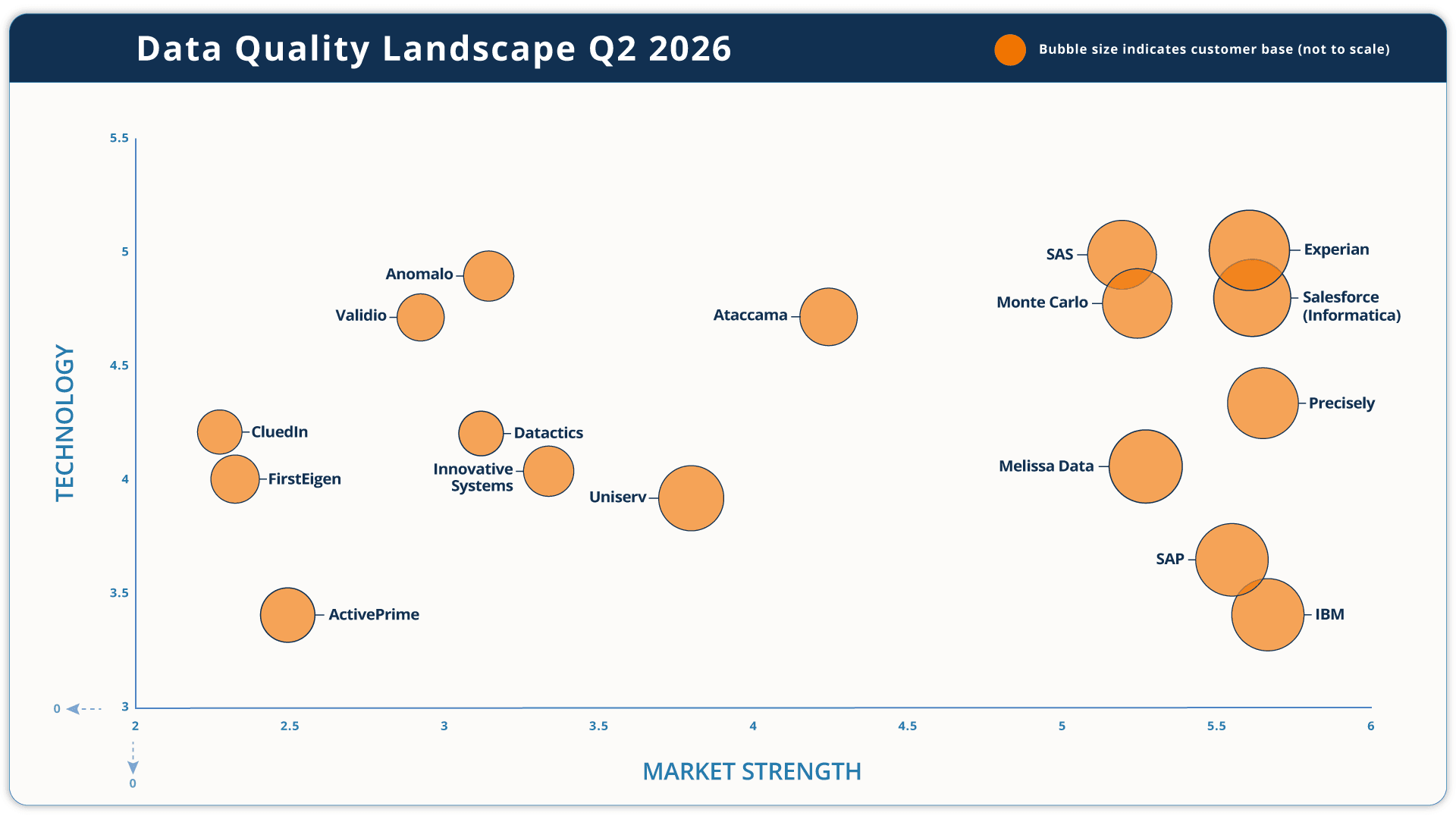
The diagram that follows shows the major data quality vendors, displayed in three dimensions. See below for definitions of these.